





Artificial Intelligence is moving from static chatbots to autonomous reasoning systems, and Kimi K2 AI by Moonshot AI stands right at that frontier.
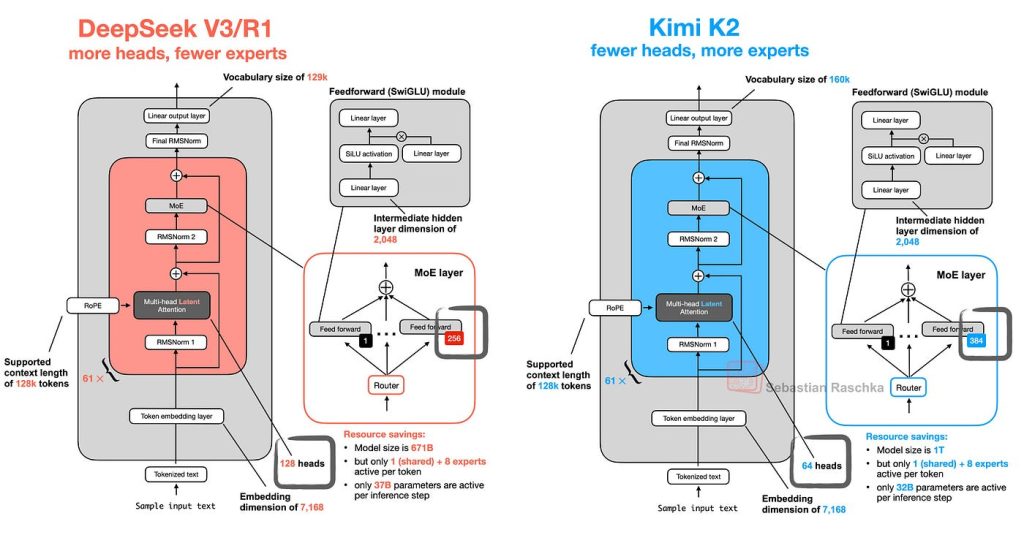
Launched as part of Moonshot’s open-source innovation push, Kimi K2 introduces a Mixture-of-Experts (MoE) design with over 1 trillion parameters—yet activates only 32 billion at once, striking a rare balance between scale and efficiency.
With a 128K-token context window, advanced tool-calling abilities, and multi-step reasoning, Kimi K2 isn’t just another chatbot. It’s an agentic AI model built to think, plan, and execute complex research or development tasks across domains—coding, analytics, policy, and academic research included.
This article explores Kimi K2’s complete feature set, project roadmap, variants, and how it could reshape the future of AI development for both open-source communities and enterprise users.
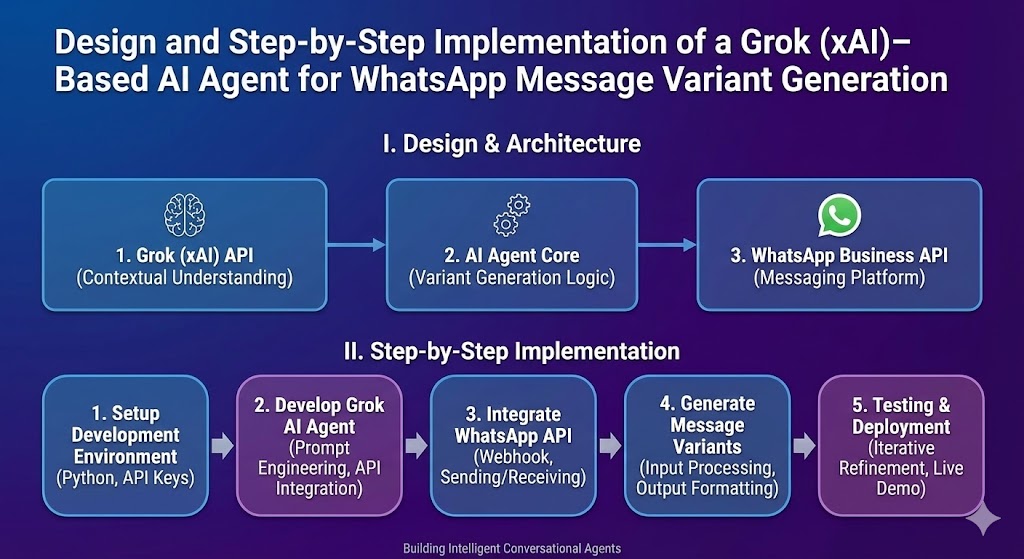


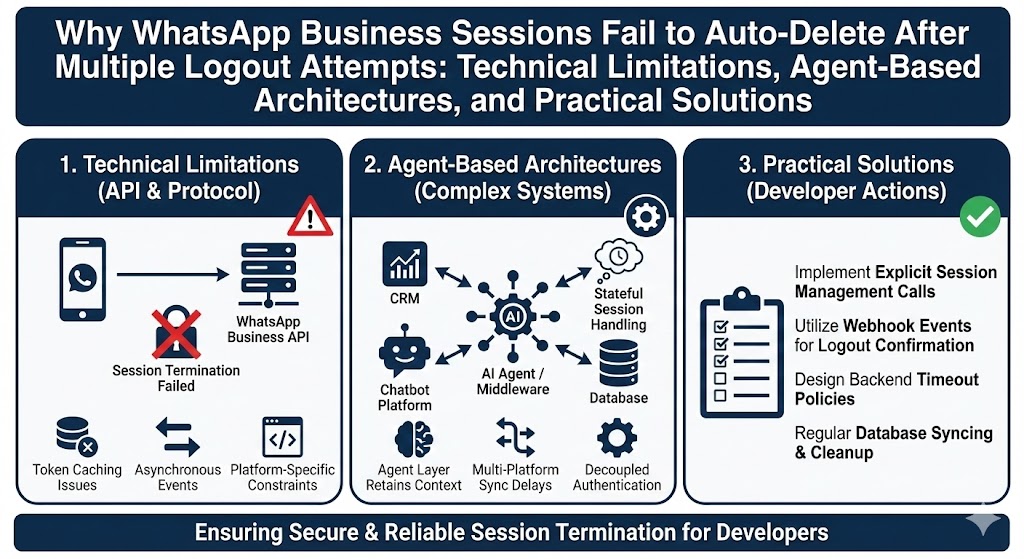
What is Kimi K2?
Kimi K2 is a large-language-model (LLM) series designed around agentic intelligence, meaning it’s built not just to respond to prompts, but to plan, orchestrate tools, reason multi-step, and act more autonomously. moonshotai.github.io+1
Here are some headline specs:
- It uses a Mixture-of-Experts (MoE) architecture: total ~1 trillion parameters, but only ~32 billion “activated” per inference. arXiv+1
- It supports very long context windows — e.g., 128 K tokens (and in some variants even up to ~256K).
- It emphasizes tool-use and sequential “thinking” over simply generating text.
- It is released (in many cases) under a modified MIT license, making it accessible for broader research / deployment.
So in short: it’s a “next-generation” open-source friendly AI model built by Moonshot AI (a Beijing-based company) with ambitions of bridging high performance and accessibility.
Key Features & Technical Highlights
Here’s where it gets interesting — the features that distinguish Kimi K2 from many previous models.
1. Mixture-of-Experts Architecture
- The MoE structure means many “expert” sub-networks exist, and only a subset are activated per token/input. This enables large total capacity (1T params) with more manageable inference cost (~32B active). arXiv+1
- They used a custom optimizer (“MuonClip” in their demo) to deal with training instability at scale. arXiv
2. Long-Context and Multi-Step Reasoning
- Context windows of 128K tokens (and even 256K in later versions) allow it to take in very large inputs — long documents, code bases, conversation history, etc. DataCamp+1
- It is designed for tasks not just of “single prompt → answer” but “plan → tool-use → observe → revise” workflows. E.g., it may call search or code execution tools, then incorporate output, refine, etc. c3.unu.edu+1
3. Agentic Tool Integration
- The model isn’t just for text generation: it can be set up to orchestrate tool calls (web search, execute code, database queries, etc) sequentially — 200-300 tool calls in a session are cited in some write-ups. DataCamp
- This opens the door for building agents: think automatic research assistants, code generation + deployment pipelines, autonomous document analysis systems.
4. Strong Performance on Coding / Reasoning / Benchmarks
- On coding‐related benchmarks (LiveCodeBench, SWE-bench, etc) Kimi K2 shows competitive results for open-source models. Analytics Vidhya+1
- On reasoning tasks, especially those requiring planning and tool use, it claims to beat or match some proprietary models in certain metrics. c3.unu.edu+1
5. Accessible Licensing & Deployment Options
- The model weights are made available under a modified MIT license, encouraging research and broader use. GitHub
- Because of its efficient architecture (only 32B active params) and quantisation efforts, it is more feasible to deploy than some huge proprietary models. moonshotai.github.io
Project Details – Timeline, Variants, Use Cases
Let’s pull together how the project is structured.
Variants
- Kimi-K2-Base: the foundational model, useful for fine-tuning and research. GitHub
- Kimi-K2-Instruct: instruction-tuned for general chat/agent tasks. Analytics Vidhya
- Kimi-K2 Thinking: A variant emphasising deeper reasoning, multi-step tool integration, long horizon agency. DataCamp+1
Data / Training
- Pre-training: ~15.5 trillion tokens used in the sample academic survey. arXiv+1
- Post-training: Includes agentic data synthesis, reinforcement learning from environment interactions. arXiv
Usage / Deployment
- Accessible through API (in their platform) or download for local / self-host research. moonshotai.github.io
- Use cases discussed include:
- Code generation + debugging (large code bases) because of long context window. Second Talent
- Research assistance: processing long documents, extracting insights, chaining tasks.
- Agentic workflows: e.g., “build a landing page + deploy it,” “analyze multi-source data + summarise.”
- Business/enterprise applications: long-form context, complex reasoning rather than simple Q&A.
Why It Matters
There are a few reasons this model signals something important:
- The shift from “static chat model” → “agentic, tool-oriented, long-horizon reasoning model.” (As one blog put it, it’s like moving from an intern to a project manager model.)
- Open-weight, research accessible: lowers the barrier for advanced AI capabilities, which means more organizations will have access beyond the big proprietary players.
- With clever architecture (MoE + long context + tool orchestration), you can get very high performance in new problem classes without necessarily needing the largest dense models.
- Opens up practical use-cases: long transcripts, large codebases, detailed analysis workflows become more feasible.
How You Might Use It (Use-Case Scenarios)
Here are some concrete scenarios where Kimi K2 could shine (you can pick/adapt for your own context).
- Large-scale Document Research: Suppose you have dozens of PDF reports, meeting transcripts, and raw data logs. Feed them into Kimi K2 (thanks to the long context window), ask it to plan a summary, extract insights, and even propose next steps.
- Coding Project Assistant: You’re working on a big project (say 100k+ lines), you want the AI to find bugs, refactor modules, generate unit tests, explain architecture. The model’s long-context + code-specific benchmarks make it well-suited.
- Agentic Workflow Builder: For example: “Given this dataset + target business goal, design the data pipeline, generate code, deploy to cloud, monitor errors.” Kimi K2 could orchestrate tool calls (search, code gen, cloud commands) in sequence.
- Strategic Analysis & Planning: You might be in business / policy / research domain and need not just answers but a structured plan: break down goals, identify research gaps, schedule tasks, monitor progress. The “thinking” variant is designed for that.
Limitations & Things to Consider
No tech is flawless, so here are some caveats:
- While highly capable, it may still not beat human specialists in all narrow domains (especially ones requiring domain-expert judgement).
- Tool orchestration requires proper setup: you’ll need infrastructure for tool-calling (APIs, permissions, etc) if you want full agentic features.
- The hardware / compute cost: Even though “only 32B active params” is more efficient than a full 1T dense model, the architecture is still non-trivial to self-host if you’re not prepared.
- Ethical / compliance concerns: As with all LLMs, use-case matters. If you’re deploying for public or regulated domain, plan for oversight, guardrails, data-privacy.
- Licensing & attribution: Although the model is open, the “modified MIT license” requires attribution for commercial services etc.
Conclusion
Kimi K2 AI represents a major leap toward the era of agentic artificial intelligence—models that can reason deeply, use tools, and maintain context over long interactions.
Its Mixture-of-Experts architecture, long context window, and multi-agent orchestration set it apart from most open-source LLMs, giving researchers, developers, and organizations a powerful foundation for automation, innovation, and large-scale analysis.
By combining high performance, flexible deployment, and open licensing, Kimi K2 redefines what an accessible next-generation AI model can be. Whether you’re a data scientist, software engineer, or academic researcher, this model offers a rare mix of technical strength and real-world usability—a glimpse of how intelligent systems will soon work alongside humans in every field.