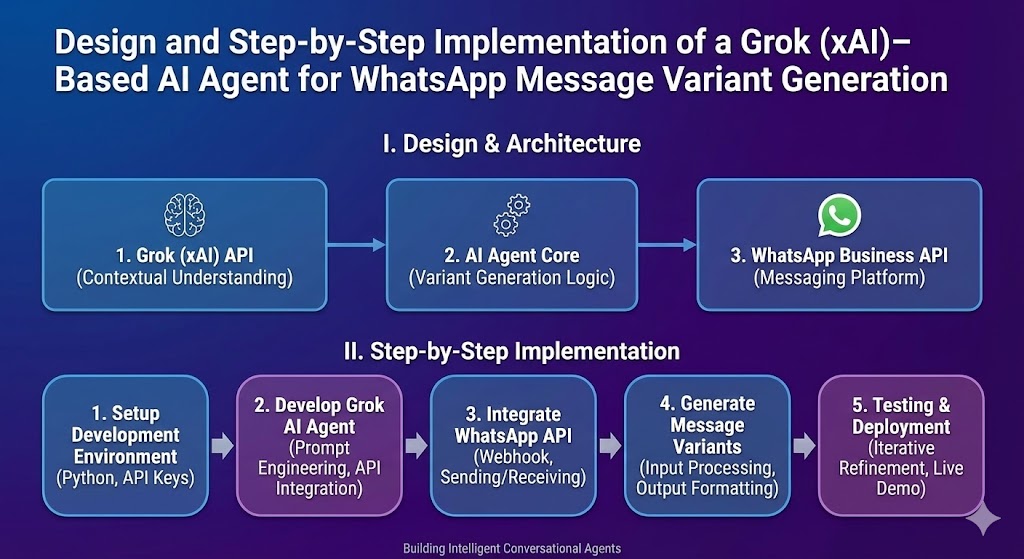

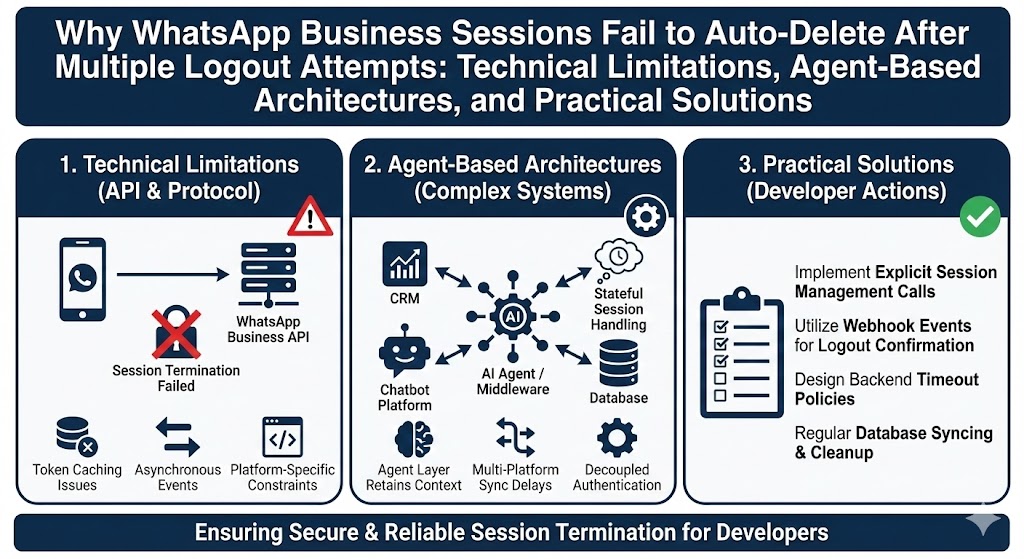


Data collection is the backbone of every Data Science project. No matter how advanced your algorithms or how powerful your computing systems are, the quality of your insights will always depend on the quality of the data you work with. In simple terms: better data leads to better decisions.
In today’s digital world, every action—whether it’s a social media post, online purchase, health record, or sensor reading—generates data. Organizations across industries rely on this data to understand trends, optimize operations, enhance customer experiences, and make informed business decisions. For a data scientist, knowing how and where to collect this data is one of the most essential skills.
This lecture explores the fundamental methods of data collection used in real-world data science workflows. You will learn how data is gathered from databases, APIs, websites, public repositories, and traditional sources like surveys or sensors. We will also discuss the difference between primary and secondary data, why data quality matters, and how beginners can start working with reliable datasets.
By understanding the complete landscape of data sources, you will be equipped to build your own datasets, access large-scale information, and prepare data for cleaning, analysis, and modeling—forming the foundation for every upcoming step in your Data Science journey.
What Is Data Collection in Data Science?
Data collection in Data Science refers to the systematic process of gathering information from various sources to analyze, interpret, and use for decision-making or model development. It is the first and most fundamental step in the Data Science pipeline. Without reliable data, even the most sophisticated algorithms cannot produce accurate or meaningful results.
In Data Science, data collection is not simply about extracting information—it involves identifying the right sources, understanding the structure of the data, and ensuring that the collected information is relevant, complete, and usable. The goal is to compile a dataset that accurately represents the problem you want to solve.
Data can come from countless places: websites, sensors, surveys, mobile devices, APIs, public databases, or internal company systems. Depending on the project, a data scientist may collect structured data (like tables and Excel sheets), semi-structured data (like JSON or XML), or unstructured data (like images, audio, or text).
Why This Step Matters
The entire success of a data project depends on the input data. High-quality data ensures:
- Clear patterns and trends
- Strong and reliable machine learning models
- Accurate predictions
- Better decisions and insights
Poor-quality data, on the other hand, leads to misleading conclusions and failed models.
What Data Collection Involves
The process typically includes:
- Identifying the problem or question
- Determining what type of data is needed
- Locating potential data sources
- Gathering raw data using tools or methods
- Storing and organizing the collected data
- Ensuring the data is in a usable format
Example Scenario
If a company wants to predict customer churn, the data collection stage may involve gathering:
- Customer profiles
- Transaction history
- Support tickets
- Website/app activity
- Customer feedback
All of this data must then be compiled before analysis can begin.
In short, data collection lays the foundation for every downstream activity in Data Science, from cleaning and exploration to modeling and deployment. The better the data collection process, the more successful and accurate the project will be.
Why Data Collection Matters
Data collection is not just the starting point of a Data Science project—it is the factor that determines its ultimate success or failure. Every insight, visualization, prediction, or business recommendation is built on the strength of the collected data. Even the most advanced machine learning algorithms cannot compensate for incomplete, inaccurate, or irrelevant data.
1. Foundation for Accurate Analysis
Accurate insights can only come from accurate data. When the collected data is consistent and representative, your analysis becomes more reliable. This allows organizations to identify real trends, patterns, and behaviors rather than misleading signals.
2. Essential for Machine Learning Models
Machine learning algorithms learn from data. The quality, variety, and volume of the data determine how well a model can generalize and make predictions in the real world. Good data leads to strong models; poor data leads to biased, unstable, or weak models.
3. Enables Informed Decision-Making
Data-driven decisions reduce guesswork. Companies rely on data to:
- Optimize marketing campaigns
- Improve product performance
- Reduce costs and risks
- Enhance customer experiences
- Identify new opportunities
Without proper data collection, decision-makers lose a major competitive advantage.
4. Helps Understand Users and Behaviors
Data reveals how users interact with products, services, and systems. This understanding is crucial for:
- Personalization
- Customer segmentation
- User journey optimization
- Retention strategies
Organizations that understand their users make better strategic decisions.
5. Ensures Compliance and Ethical Use
Proper data collection ensures that data is gathered legally, ethically, and transparently. This includes:
- Following privacy laws (like GDPR)
- Collecting only necessary data
- Ensuring user consent
- Maintaining data security
Ethical data collection builds trust and prevents legal issues.
6. Saves Time and Resources
Good data collection processes reduce the need for excessive cleaning and correction later. When data is collected correctly:
- Less time is spent fixing errors
- Data preprocessing becomes easier
- The entire workflow becomes more efficient
In professional environments, this can save thousands of dollars in wasted time.
Types of Data Sources
Data scientists work with a wide range of data sources depending on the problem they are trying to solve. These sources vary in format, structure, accessibility, and reliability. Understanding these categories helps beginners identify where to find data and how to use it effectively.
Broadly, data sources in Data Science can be divided into two major categories: Primary Data Sources and Secondary Data Sources. Within these categories, data can also be structured, semi-structured, or unstructured.
1. Primary Data Sources
Primary data is collected directly by the data scientist or organization for a specific purpose. It is original, firsthand information gathered through:
- Surveys and Questionnaires
Data collected directly from respondents through online forms, feedback tools, or in-person surveys. - Interviews
Qualitative data gathered by speaking directly with individuals, stakeholders, or users. - Experiments
Data generated through controlled experiments, A/B testing, or scientific tests. - Sensors and IoT Devices
Real-time data from devices such as smart meters, fitness trackers, cars, and industrial sensors. - Logs and Internal Systems
Data from internal business systems—CRM logs, transaction records, app usage logs, etc.
Advantages:
✔ Highly accurate and relevant
✔ Tailored to the specific problem
✔ Up-to-date and real-time
Disadvantages:
✘ Time-consuming
✘ Can be expensive
✘ Requires technical setup
2. Secondary Data Sources
Secondary data is collected and shared by someone else but reused for your analysis. Data scientists frequently use secondary data because it is easier, cheaper, and faster to access.
Common secondary sources include:
- Public Datasets
Platforms like Kaggle, UCI Machine Learning Repository, Google Dataset Search, or government portals. - APIs (Application Programming Interfaces)
Data from services such as Twitter API, OpenWeather API, Google Maps API, or financial market APIs. - Websites and Web Scraping
Extracting publicly available structured or unstructured data from e-commerce sites, blogs, Wikipedia, etc. - Databases
Accessing external or shared SQL/NoSQL databases that store large volumes of information. - Reports, Research Papers, and Publications
Extracting data from academic studies, statistics reports, or industry insights.
Advantages:
✔ Cost-effective
✔ Easily accessible
✔ Ready-made for analysis
Disadvantages:
✘ May not be 100% accurate
✘ May lack context or completeness
✘ Requires verification and cleaning
3. Internal vs External Data Sources
Apart from primary and secondary classification, data sources are also categorized as:
- Internal Data Sources (within an organization)
Examples: sales records, customer demographics, employee data, system logs. - External Data Sources (outside an organization)
Examples: market reports, weather data, competitor data, social media content.
4. Structured, Semi-Structured & Unstructured Data Sources
Structured Data
Tabular, organized data stored in rows and columns.
Examples:
- SQL databases
- Excel sheets
- Financial reports
Semi-Structured Data
Partially organized data with tags or hierarchy.
Examples:
- JSON files
- XML
- Web APIs
Unstructured Data
Raw, unorganized data without a predefined format.
Examples:
Social media posts
Images
Text documents
Audio and video files
Top Data Collection Methods in Data Science
Data scientists use a variety of methods to gather information depending on the nature of the problem, the type of data needed, and the available tools. These methods range from manual techniques like surveys to fully automated systems such as APIs and IoT sensors. Understanding these methods helps you choose the most effective approach for your project.
Below are the most widely used data collection methods in Data Science:
1. Web Scraping
What It Is
Web scraping is the process of extracting data from websites using automated tools, scripts, or Python libraries.
What It’s Used For
- E-commerce price tracking
- Collecting product reviews
- Gathering news articles or blog content
- Extracting large volumes of text data
- Building custom datasets for NLP projects
Common Tools
- Python Libraries: BeautifulSoup, Scrapy, Selenium
- APIs Provided by Websites (when available)
Pros
✔ Collects large amounts of data quickly
✔ Useful for unstructured content like text
✔ Customizable for specific needs
Cons
✘ May require technical skills
✘ Some websites block scraping
✘ Legal/ethical concerns if not done properly
2. APIs (Application Programming Interfaces)
What It Is
APIs allow data scientists to access structured data directly from service providers through HTTP requests.
Examples of APIs
- Twitter API for tweet data
- OpenWeather API for weather information
- Google Maps API for location data
- Financial APIs for stock prices or crypto data
Pros
✔ Clean, structured data
✔ Reliable and real-time
✔ Easier than scraping
Cons
✘ Rate limits
✘ Requires API keys
✘ Some advanced features may be paid
3. Databases (SQL & NoSQL)
What They Are
Organizations often store their data in:
- SQL databases (MySQL, PostgreSQL, SQL Server)
- NoSQL databases (MongoDB, Cassandra, Firebase)
What It’s Used For
- Customer records
- Transactions
- Operational data
- Log files
- Business intelligence
Pros
✔ Highly structured
✔ Secure and scalable
✔ Supports large datasets
Cons
✘ Requires knowledge of SQL/queries
✘ Access restrictions in many companies
4. Surveys & Questionnaires
What It Is
Directly collecting user responses through online forms or physical surveys.
Common Tools
- Google Forms
- Typeform
- SurveyMonkey
Pros
✔ Firsthand, original data
✔ Great for measuring opinions or satisfaction
✔ Useful for qualitative insights
Cons
✘ Limited sample size
✘ Responses may be biased
✘ Time-consuming
5. Sensors & IoT Devices
What It Is
Collecting real-time data from devices such as:
- GPS trackers
- Heart-rate monitors
- Smart home devices
- Industrial machinery sensors
- Mobile phones
Pros
✔ Continuous real-time data
✔ High accuracy
✔ Ideal for big data
Cons
✘ Requires hardware
✘ Data volume can be enormous
✘ Complex to manage and store
6. Logs & System Monitoring Tools
Organizations generate logs from:
- Web servers
- Applications
- CRM systems
- Security systems
Used For
- User behavior tracking
- Performance monitoring
- Error detection
- Security analysis
Pros
✔ Automatically generated
✔ Rich behavioral insights
✔ Ideal for ML use cases
Cons
✘ Requires strong data engineering skills
✘ High storage costs
7. Public Data Repositories
These are ready-made datasets shared by organizations, governments, or researchers.
Examples
- Kaggle
- UCI Machine Learning Repository
- Google Dataset Search
- Government portals (data.gov)
- WHO / UN datasets
Pros
✔ Free and accessible
✔ Good for practice and projects
✔ Useful for benchmarking
Cons
✘ May be outdated
✘ Not tailored to your specific needs
8. Social Media Platforms
Data collected through:
- Tweets
- Instagram posts
- YouTube comments
- Reddit threads
Tools
- Scrapers
- APIs
- Social listening tools
Pros
✔ Ideal for sentiment analysis
✔ Large volume of unstructured data
✔ Useful for trend analysis
Cons
✘ Requires text processing
✘ Potential ethical issues
5. Open Data Portals (Public Datasets)
These platforms offer free datasets across all domains.
Recommended Sources
- Kaggle (data science projects)
- UCI Machine Learning Repository
- Google Dataset Search
- World Bank Open Data
- GitHub repositories
- Government open data portals
Great for learning, practicing ML, and building portfolios.
What Makes Data “Good” for Data Science?
High-quality datasets have:
- Accuracy (Correct values)
- Completeness (No missing data)
- Consistency (No contradictions)
- Relevance (Useful for the problem)
- Timeliness (Updated)
Good data reduces the time spent on cleaning and boosts model performance.
Common Challenges in Data Collection
- Missing or incomplete data
- Data privacy and security issues
- Inconsistent formats
- Outdated information
- Limited access to proprietary sources
A data scientist must be prepared to handle all of these.
Mini Quiz
- What is the difference between primary and secondary data?
- Name three public dataset sources.
- What is an API used for?
- Write a simple example of a data file format.
- What makes data “high quality”?
Conclusion
Data collection is the foundation of every Data Science project. Whether data comes from APIs, web scraping, databases, or public datasets, your results depend on the quality, relevance, and completeness of the information you gather. Once you have collected data, the next step is cleaning it—which we will cover in Lecture 6.